# 添加要使用的包
requests
pip3 install requests
1
BeautifulSoup
pip3 install bs4
1

# 新建工程 导入相关包
import requests
from bs4 import BeautifulSoup
1
2
2
导入相关包运行后提示如下图所示的ModuleNotFound错误,是由于环境配置问题导致。
见ModuleNotFound错误 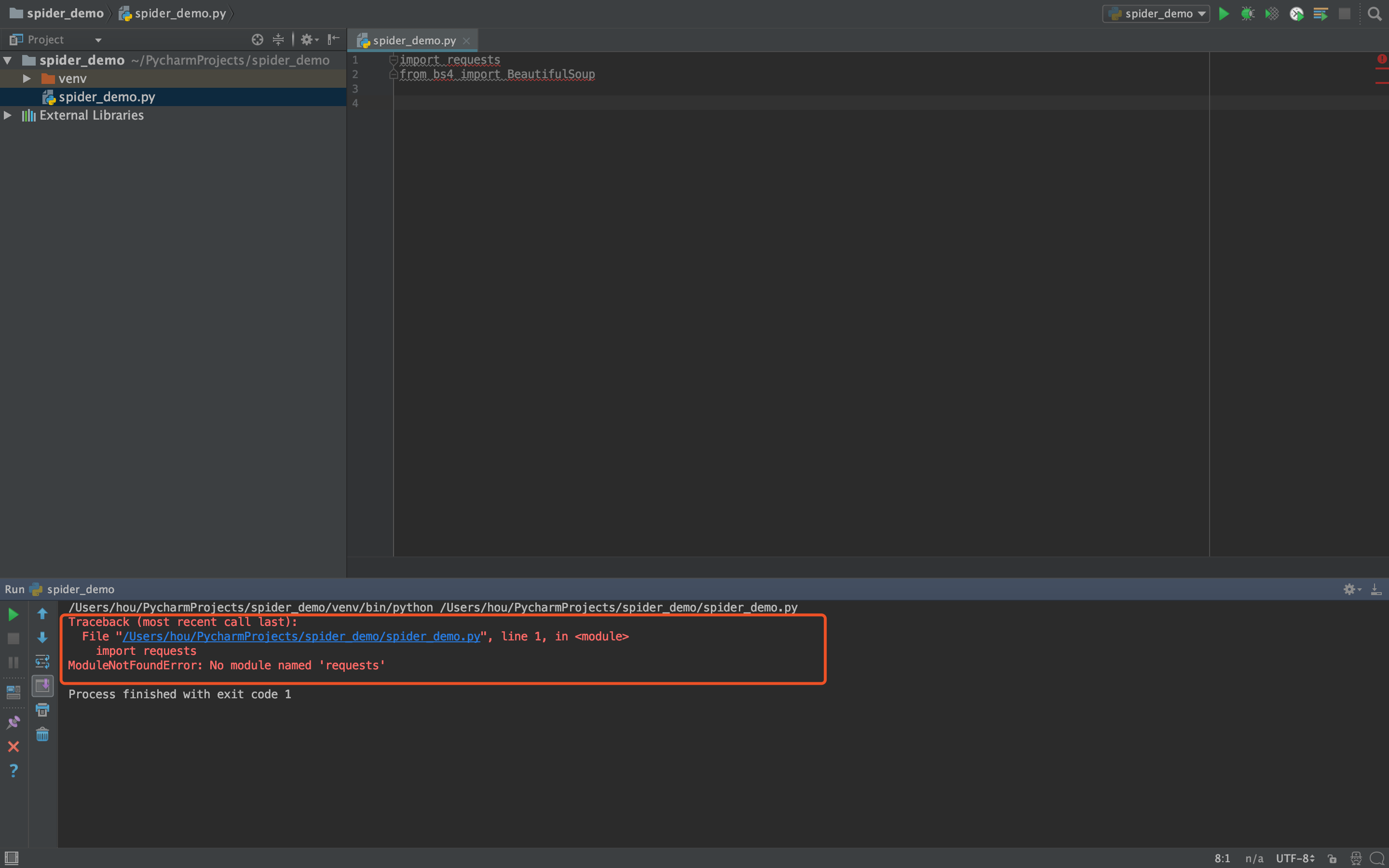
# 查看网页结构,定位爬取元素位置
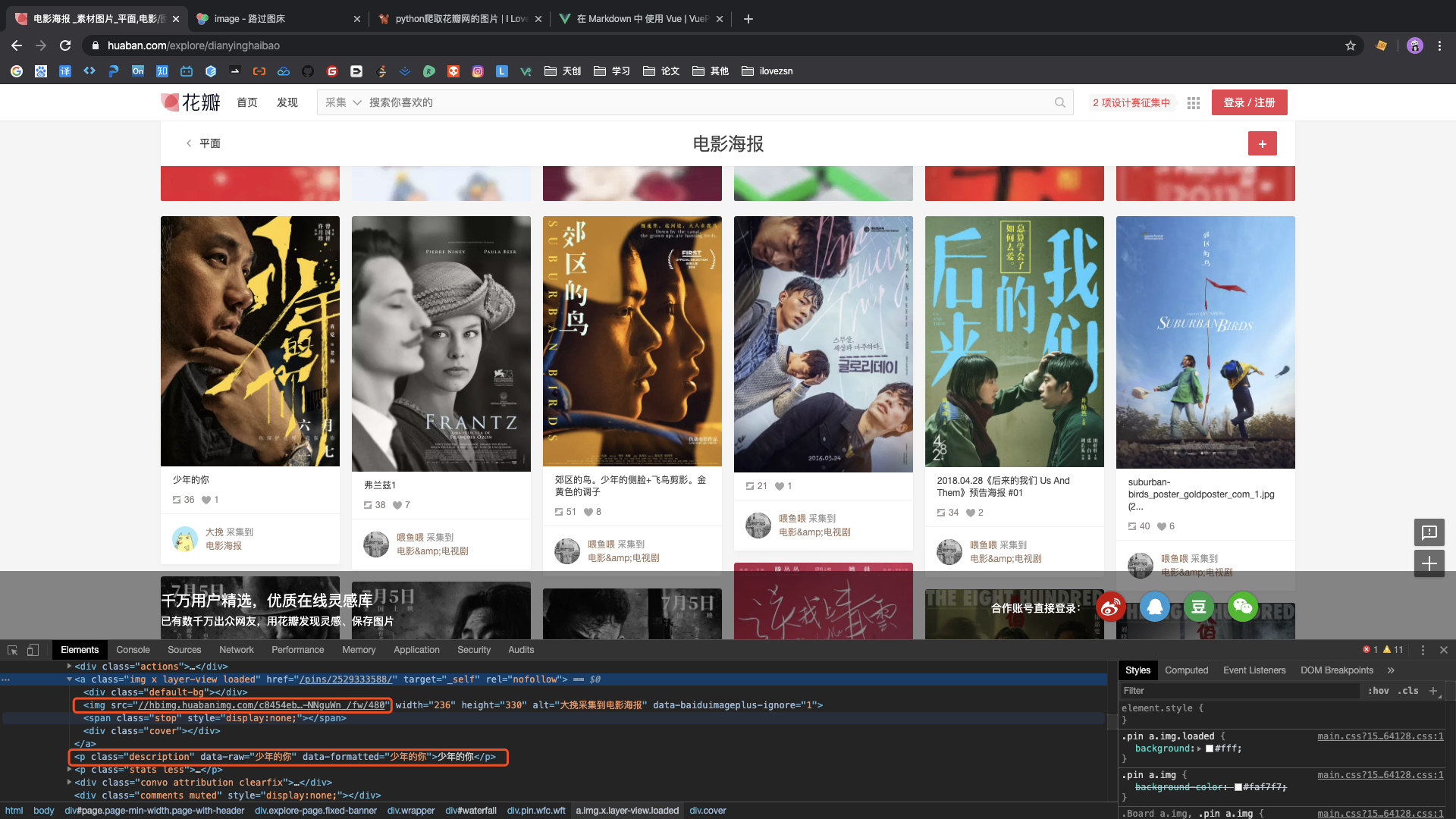
右键 -> 查看网页源代码,通过定位可以看到,要爬取的图片链接位于class="img x layer-view loaded"
的a标签下的img子标签,图片链接为img标签的src属性;图片的名字为a标签同级的p标签的内容
# 获取页面信息
定义请求头(可通过页面控制台复制)
# 定义请求头
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"origin: https": "//huaban.com",
"pragma": "no-cache",
"referer": "https//huaban.com/",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "cross-site",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
"x-client-data": "CJG2yQEIpbbJAQjBtskBCKmdygEInqDKAQjQr8oBCLywygEIl7XKAQjttcoBCI66ygEImb3KAQjOvcoB"
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
定义要爬取的url
# 定义url
url = 'https://huaban.com/explore/dianyinghaibao'
1
2
2
获取页面信息
# 爬取过程
def craw(url):
response = requests.get(url, headers)
soup = BeautifulSoup(response.content, 'lxml')
print(soup.prettify())
# 调用
craw(url)
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
执行后会获取到网页的源代码
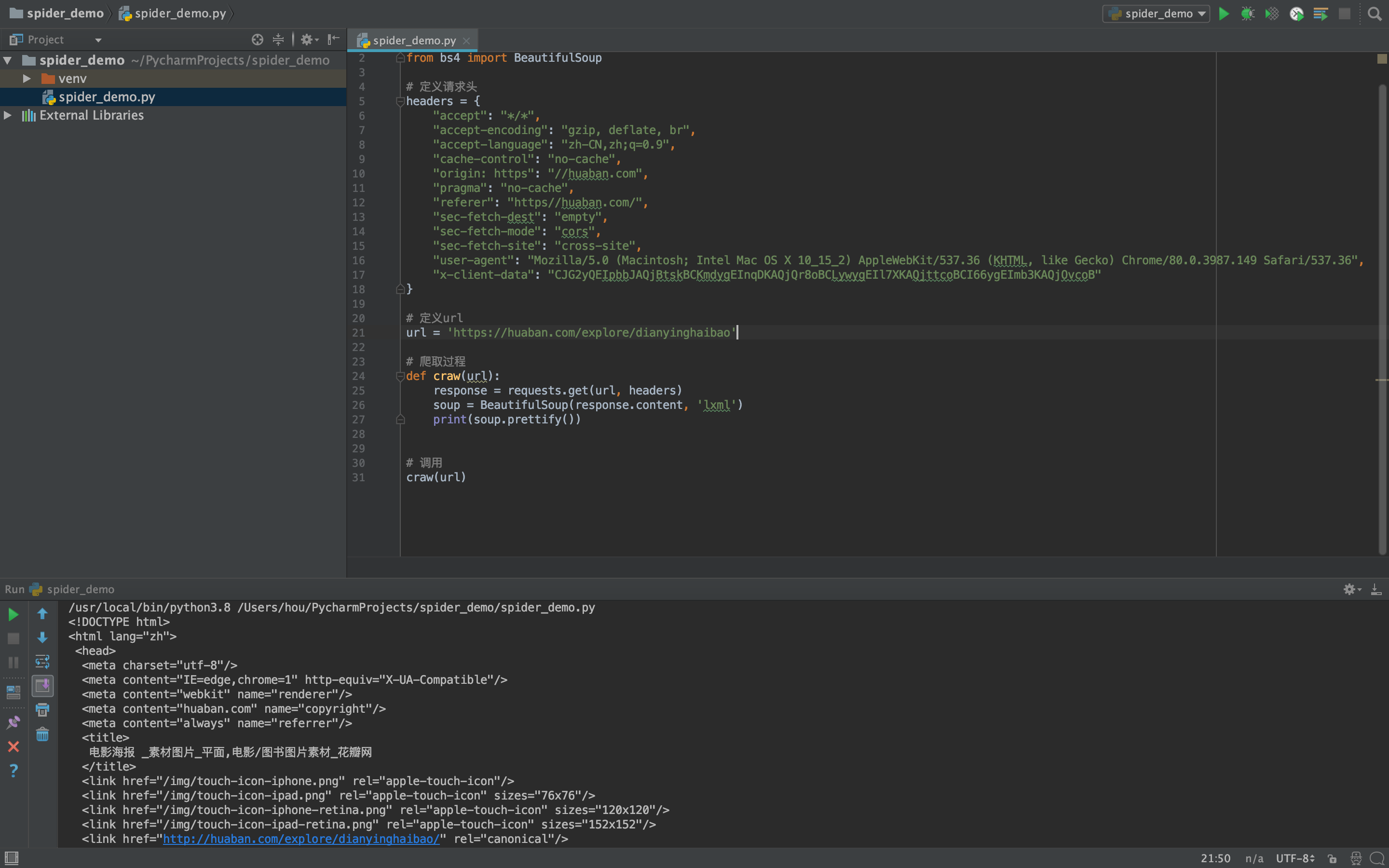
提示
如果报错如下所示,找不到'lxml'解析器的时候,通过pip3 install lxml安装解决

# 获取图片链接
# 获取图片链接
for pic_href in soup.find_all('a', class_='img x layer-view loaded'):
print(pic_href)
1
2
3
2
3
通过预想的获取指定class的a标签获取图片相关信息的时候,发现并不能正确的获取到相关结果。
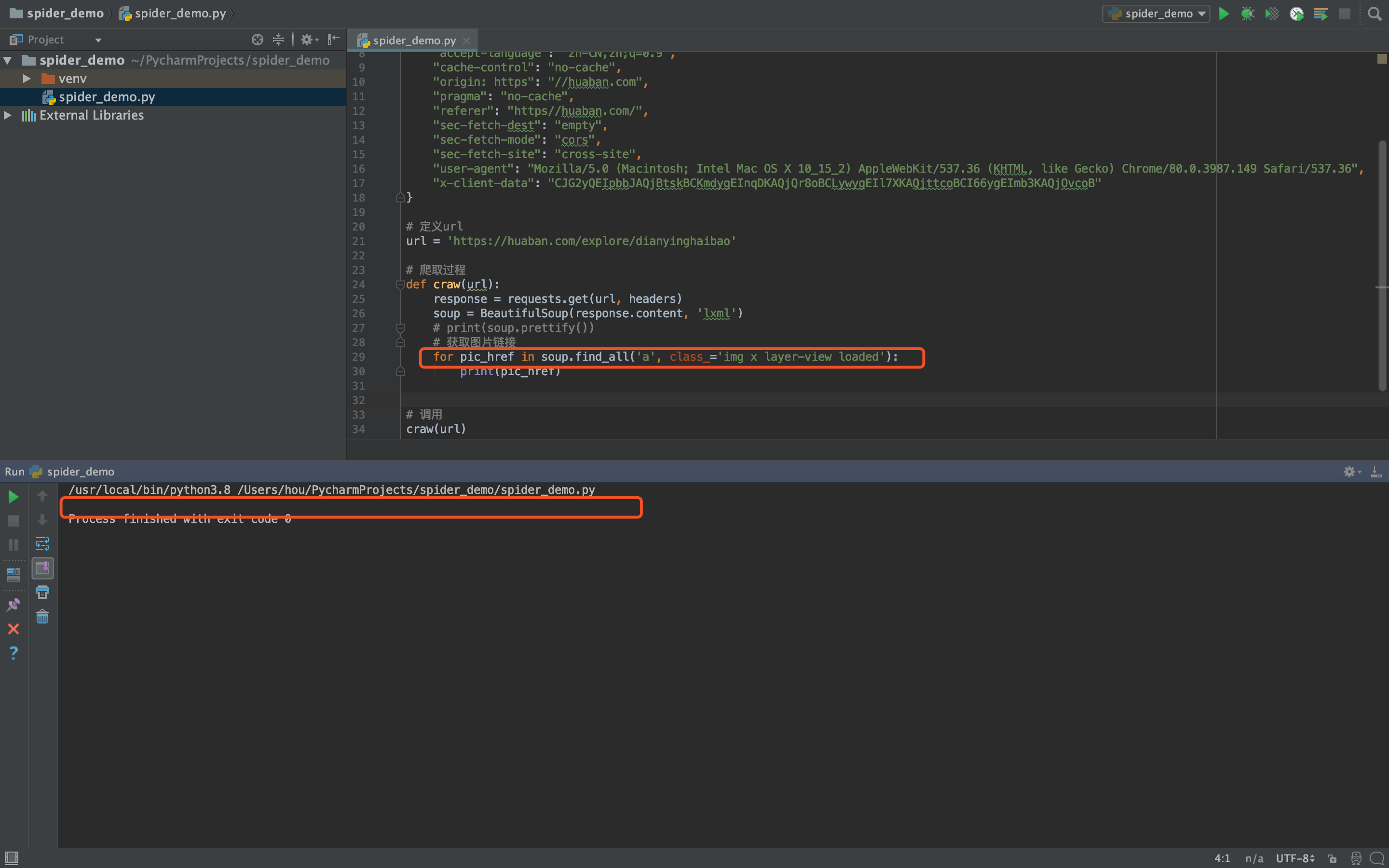
经过我仔细的分析(和baidu)之后发现,图片数据不是一开始直接加载到页面中的,而是通过异步请求获取数据后渲染到页面上。 所以对花瓣网的第一次爬取失败了 😦
# ModuleNotFound错误 解决方案
查看Preferences -> Project -> Project Interpreter,此时只会存在一个环境信息。
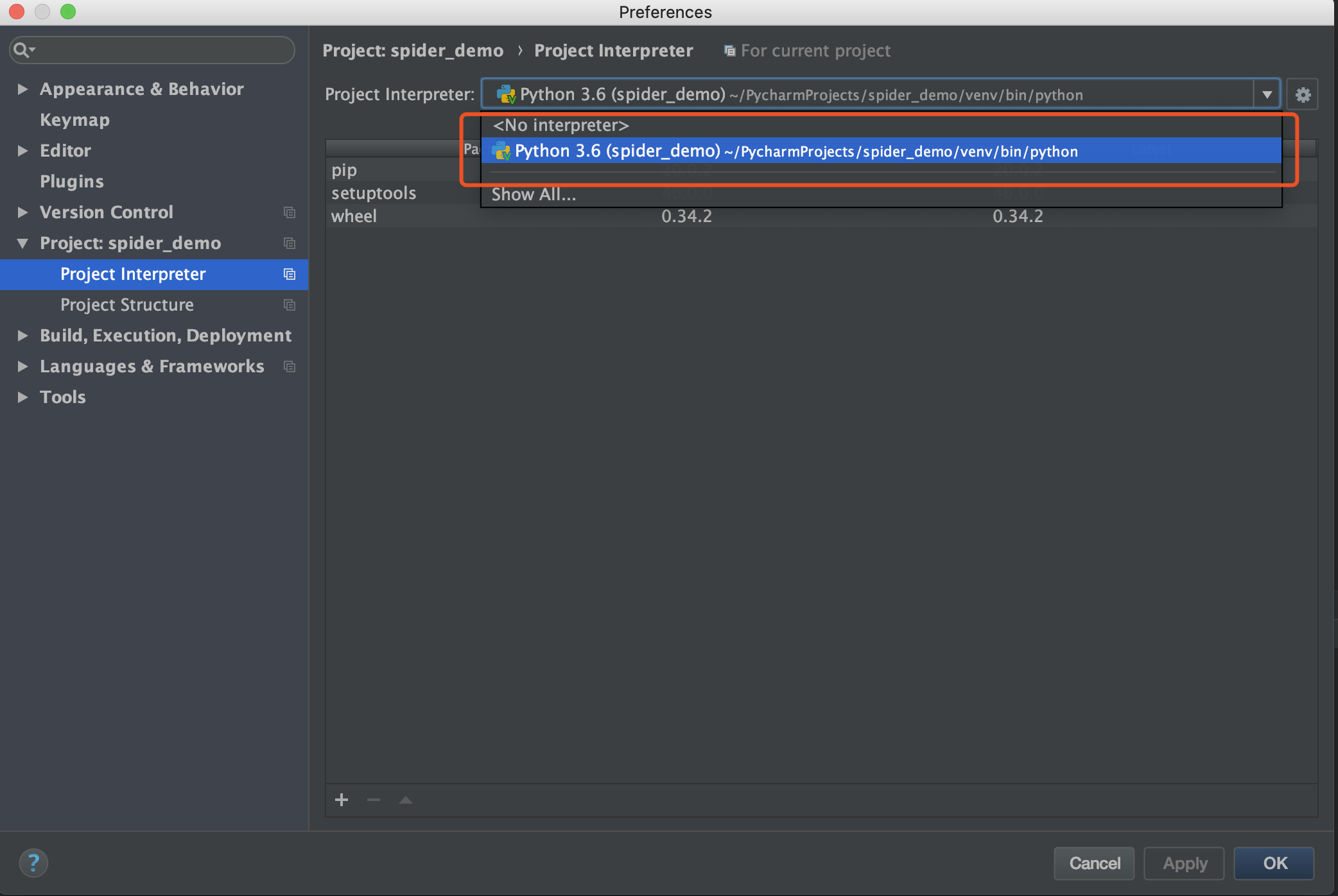
点击齿轮,选择Add Local,弹出窗口后,选择System Interpreter选项,挑选合适版本的py进行引入,确认。
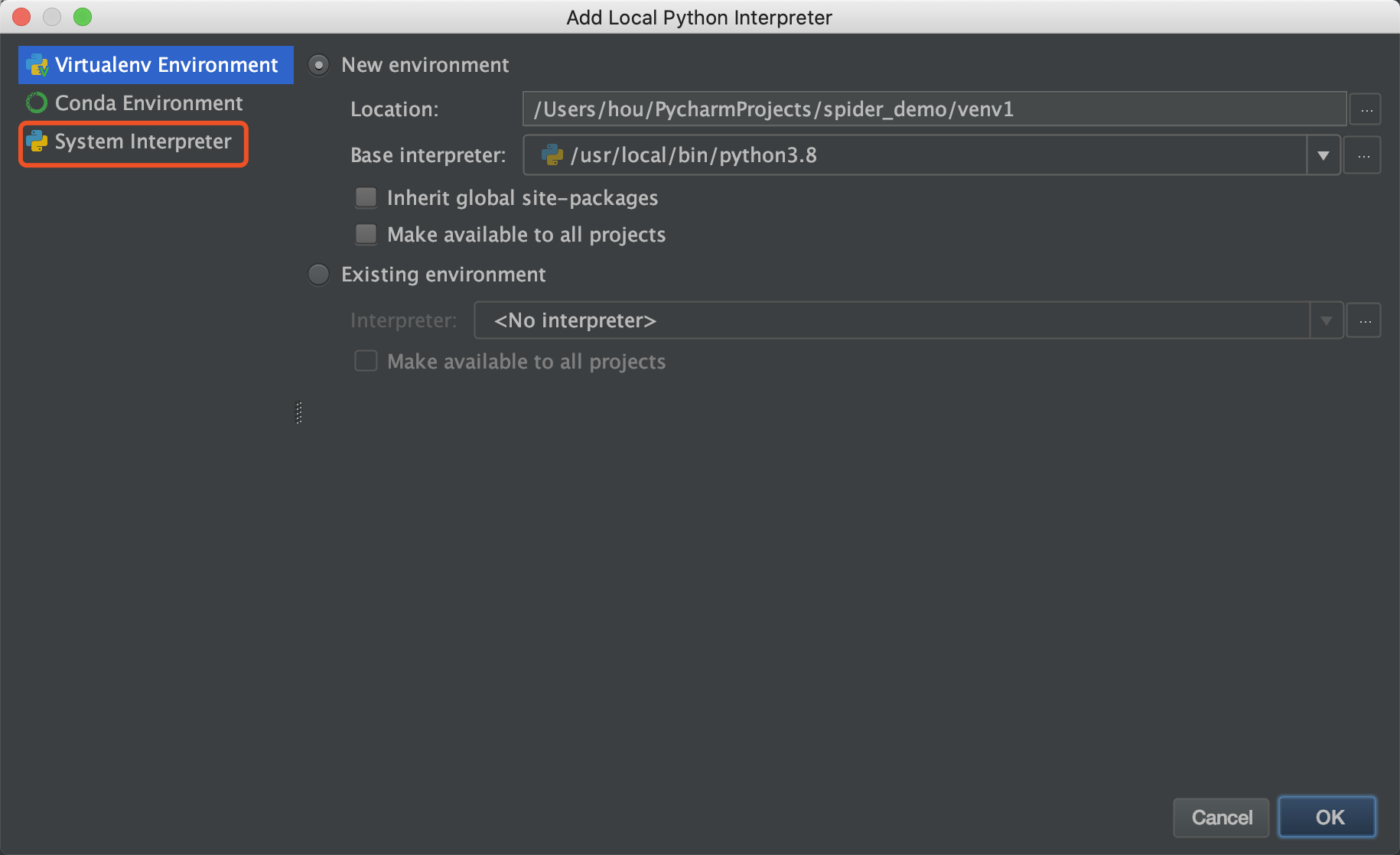
再次运行程序,无异常。