
# 重命名并新建py文件 Just Kidding
# 理智分析
当页面滑动到一定高度时,会发送一个请求,页面数据进行更新。 参数:
{
k7yykour:
max: 2526385308
limit: 20
wfl: 1
}
1
2
3
4
5
6
2
3
4
5
6
其中max为当前页面最后一张图片的pin_id, limit为本次请求的图片数量。
猜想页面的图片按照id倒序排列,当滑动到一定高度时,将当前页面最小id作为参数,去后台请求新数据。

响应的json报文中pins为新图片页面的信息。
其中pin_id与https://huaban.com/pins/进行拼接可以弹出图片的查看窗口
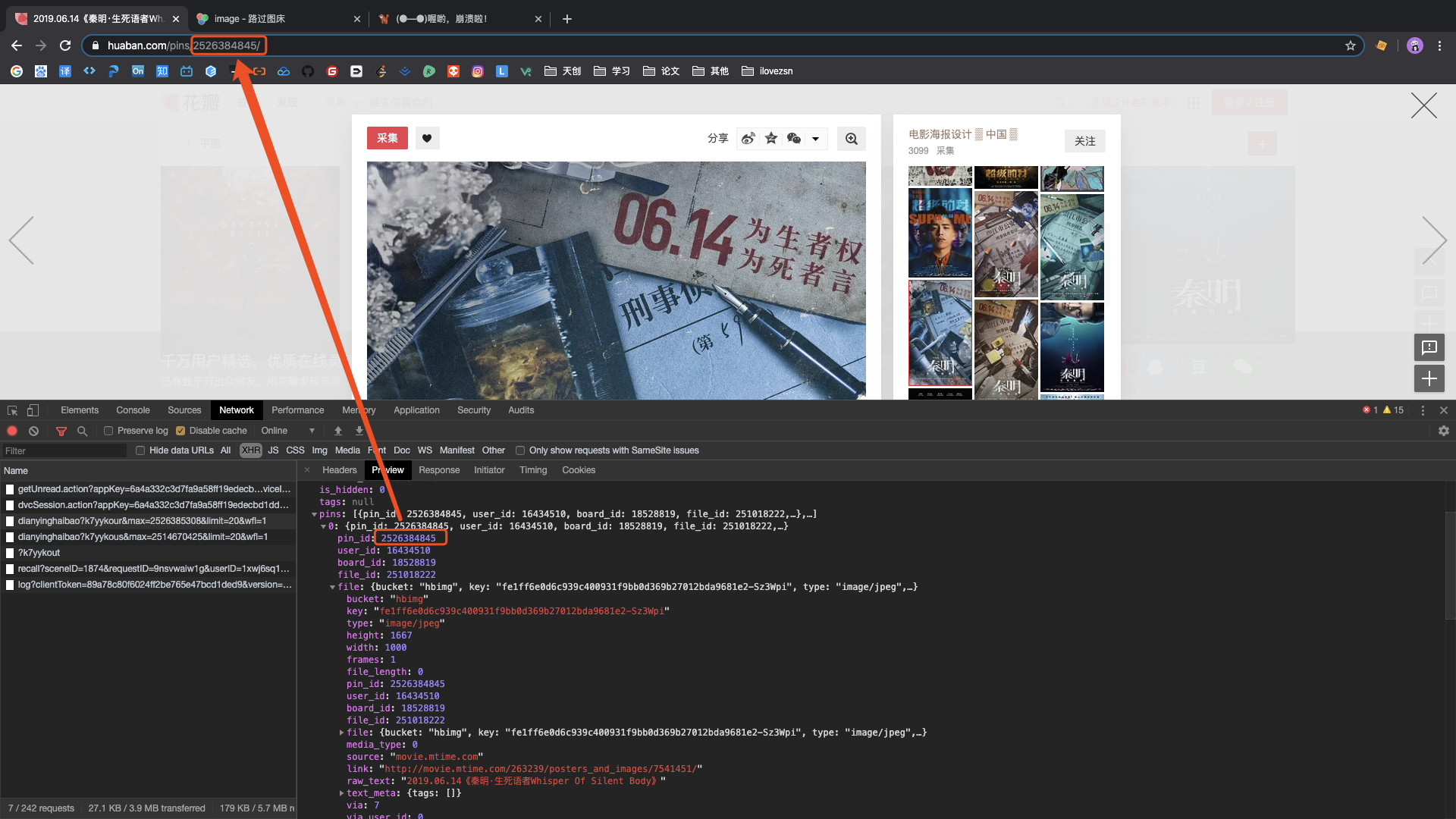
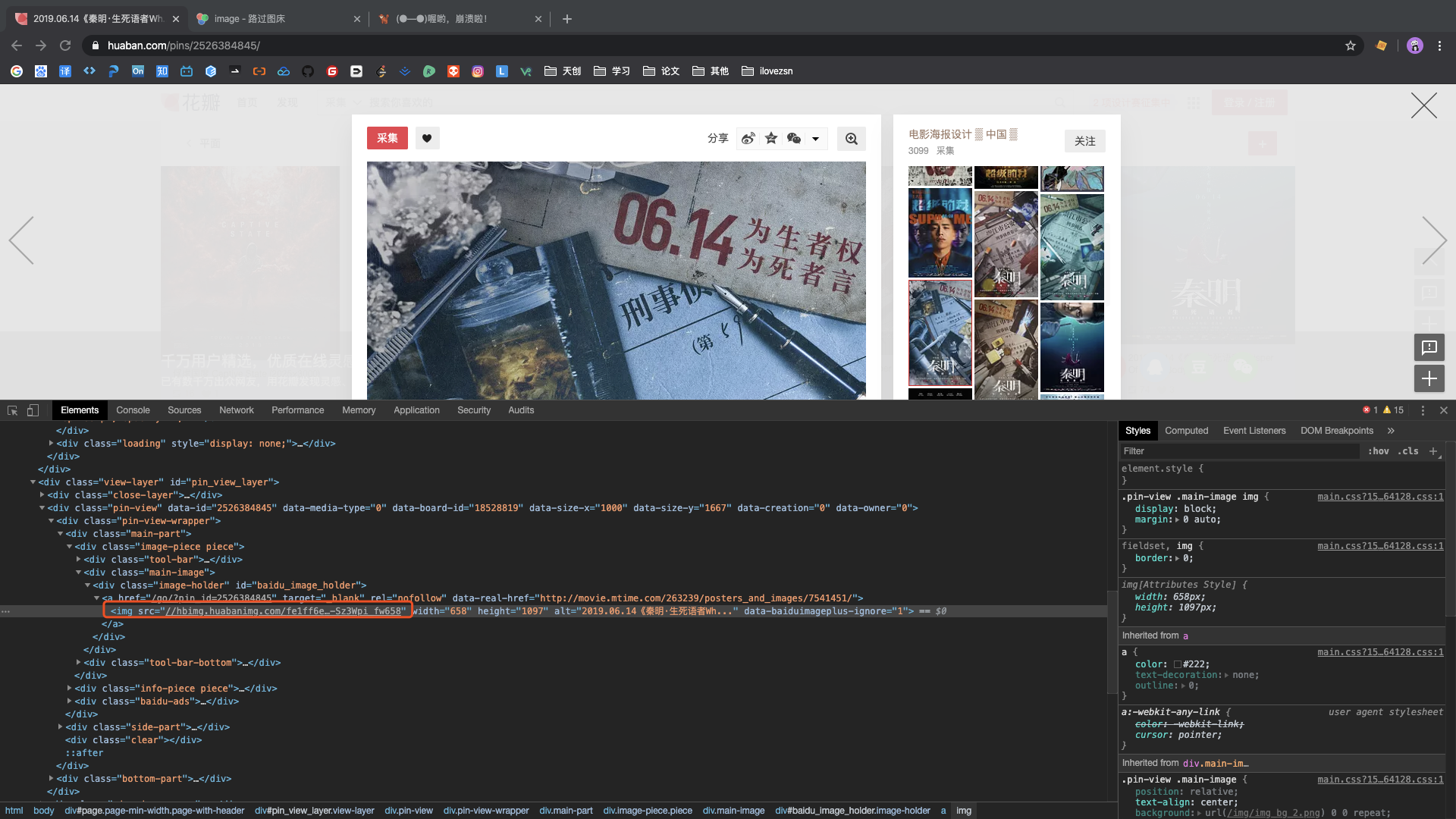
pins -> file -> key与http://hbimg.huabanimg.com/进行拼接即为图片的链接地址

# 编码开始
# 导包
import requests
1
# 设置起始最大id
点击当前页面第一张图片,根据地址栏展示,获取该图片的pin_id作为起始最大id
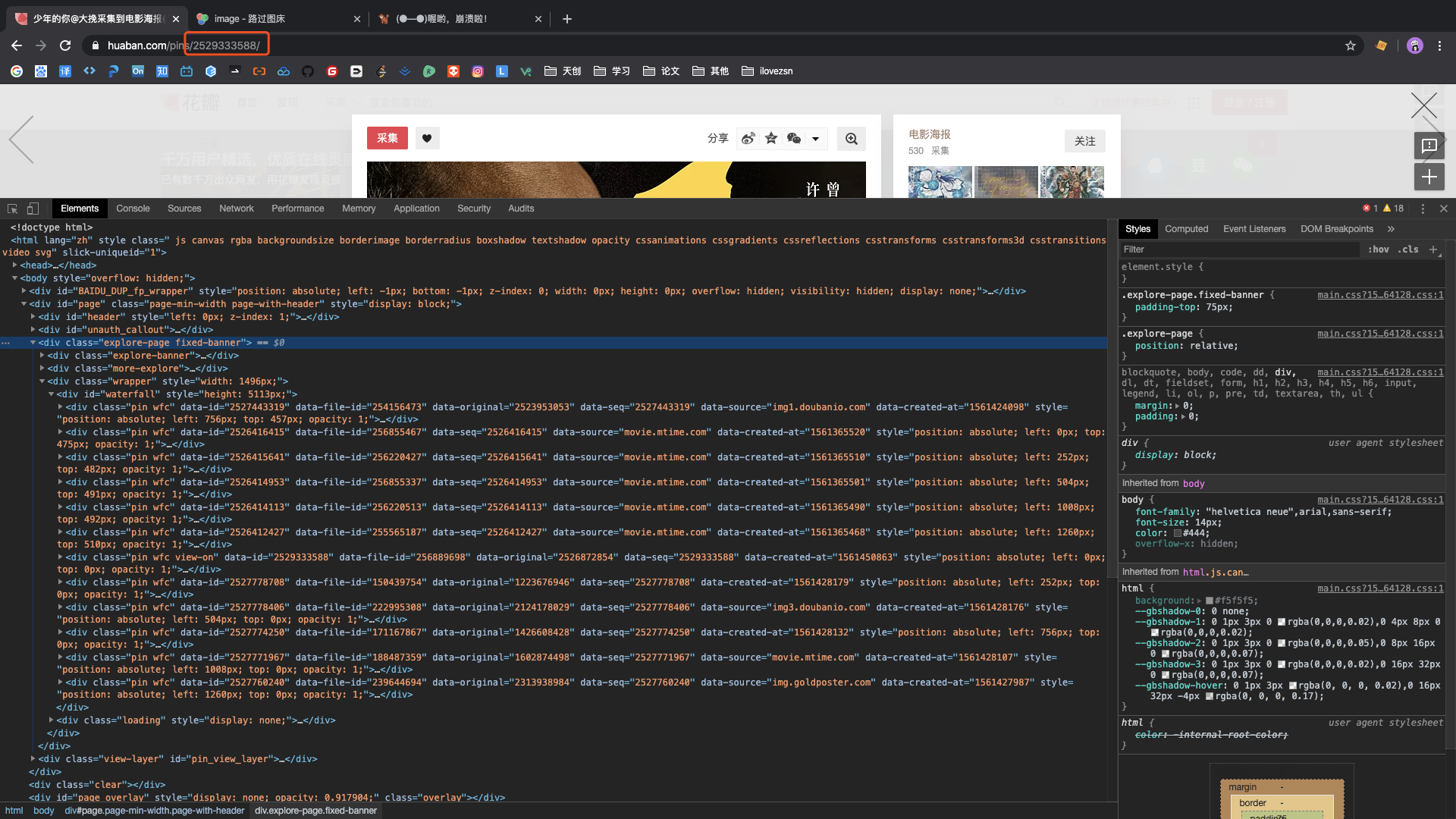
# 设置起始最大id
start_max = 2529333588
1
2
2
# 测试爬取
设置好请求必要信息,进行调用,返回结果格式与浏览器请求一致
# 定义基础url
base_url = 'https://huaban.com/explore/dianyinghaibao'
# 定义参数
params = {
'k7yykous': '',
'max': start_max,
'limit': '20',
'wfl': '1',
}
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36',
'Accept': 'application/json',
'X-Request': 'JSON',
'X-Requested-With': 'XMLHttpRequest',
}
# 爬取过程
def craw(url):
response = requests.get(url, params=params, headers=headers)
print(response.json())
# 调用
craw(base_url)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
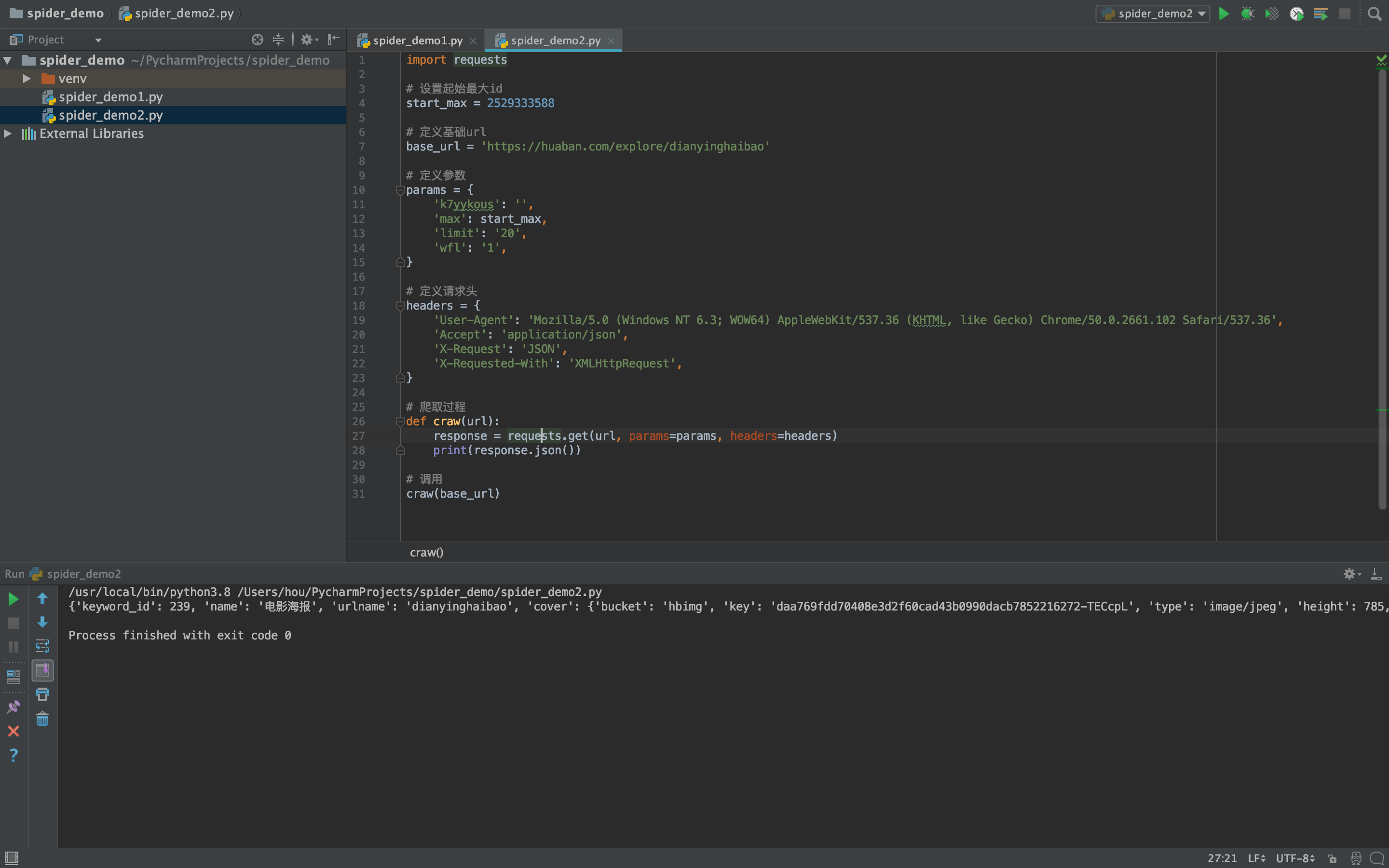
# 解析响应报文,获取图片链接
解析响应报文,获取key,与指定url拼接作为图片链接
# 定义图片基础url
img_url = 'http://hbimg.huabanimg.com/'
# 爬取过程
def craw(url):
response = requests.get(url, params=params, headers=headers)
# print(response.json())
pins = response.json()['pins']
if pins:
for pin in pins:
print(img_url + pin['file']['key'])
# 调用
craw(base_url)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
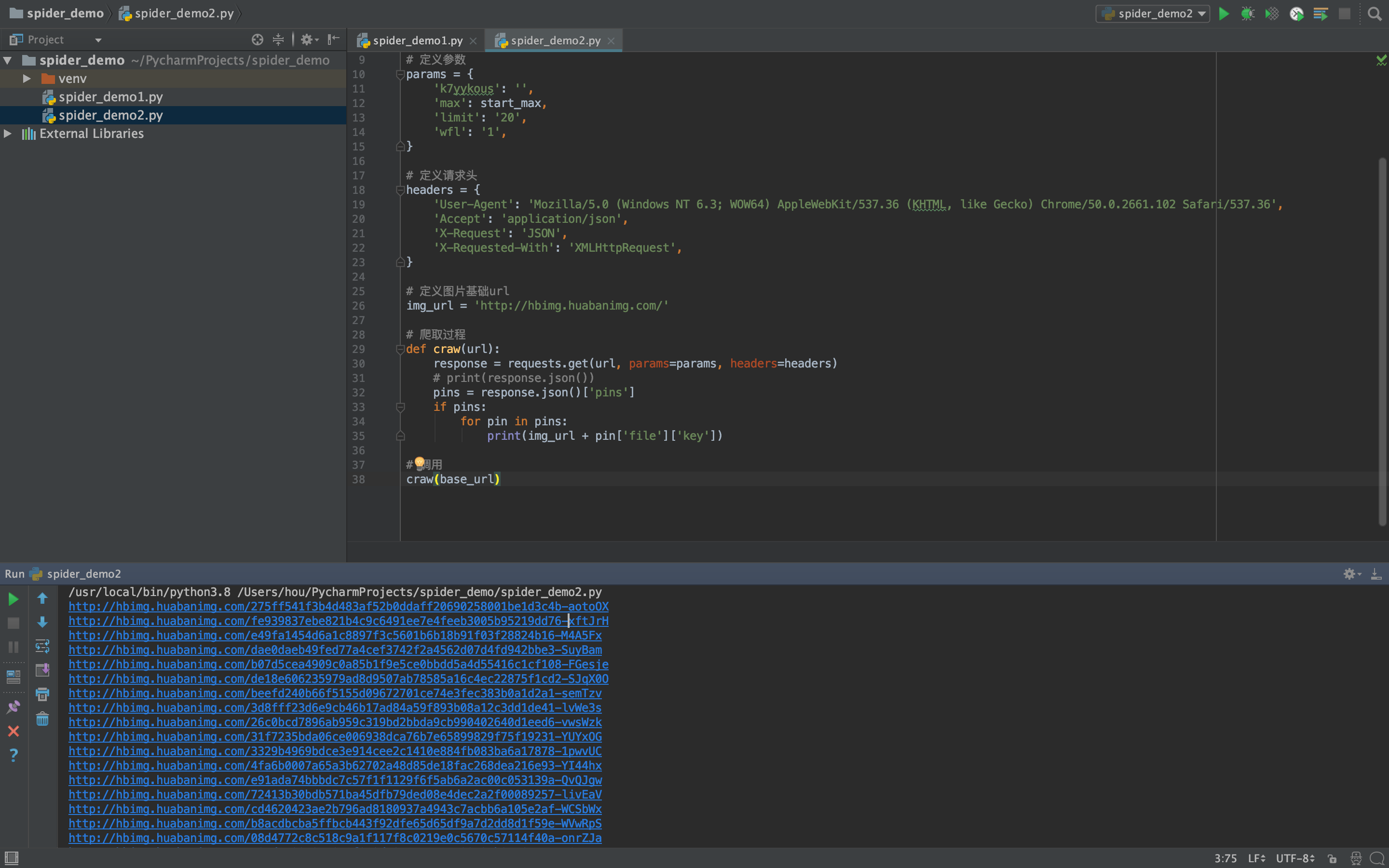
# 修改为循环获取多页数据
添加循环后需要将每页的最后一条数据的pin_id作为参数传递到获取下一页数据的请求中。
import requests
# 定义基础url
base_url = 'https://huaban.com/explore/dianyinghaibao'
# 定义图片基础url
img_url = 'http://hbimg.huabanimg.com/'
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36',
'Accept': 'application/json',
'X-Request': 'JSON',
'X-Requested-With': 'XMLHttpRequest',
}
# 定义要获取的最大页数
pages = 5
# 爬取过程
def craw(url):
i = 1
# 设置起始最大id
start_max = 2529333588
while i <= pages:
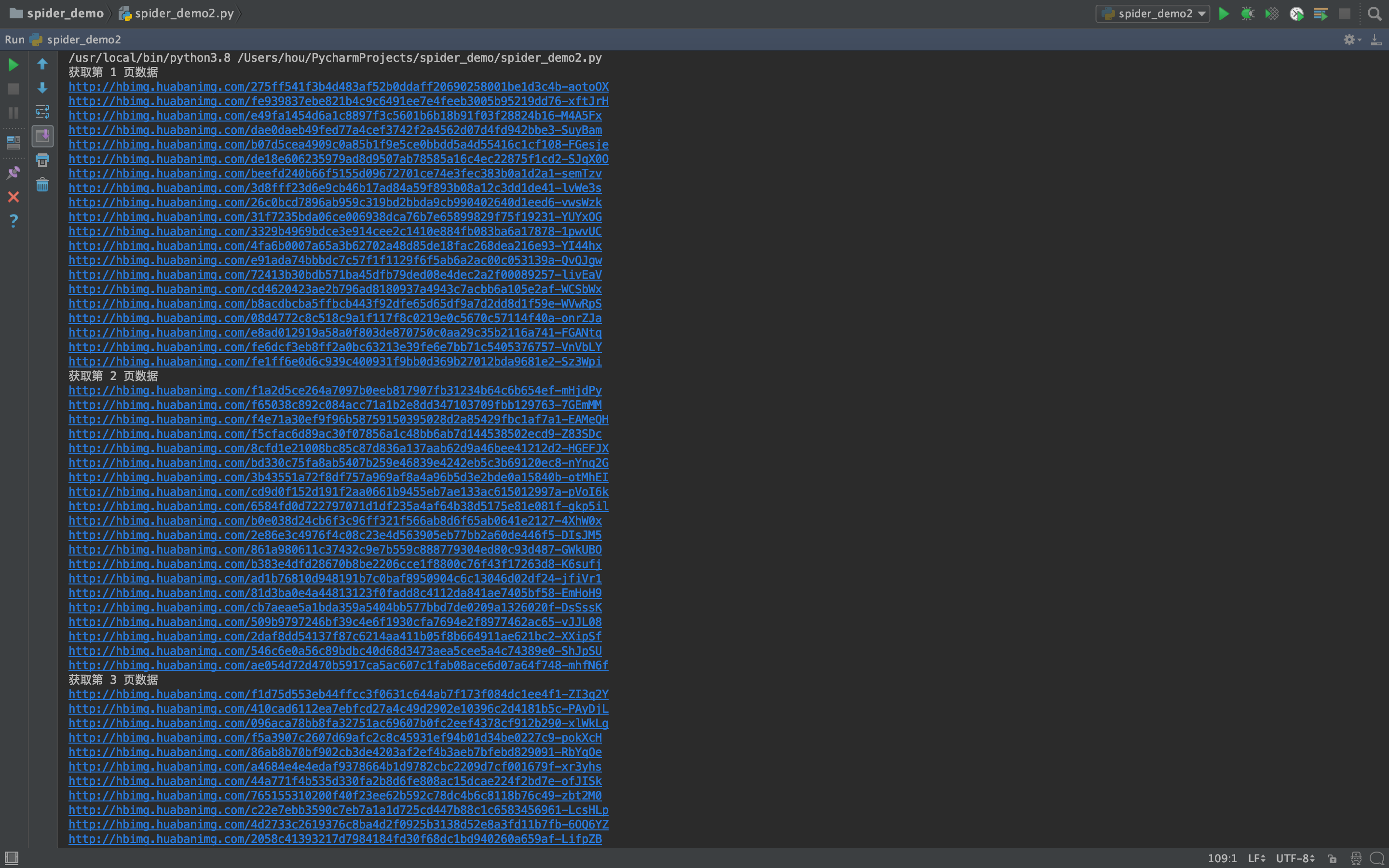
print('获取第 %d 页数据' % (i))
# 定义参数
params = {
'k7yykous': '',
'max': start_max,
'limit': '20',
'wfl': '1',
}
response = requests.get(url, params=params, headers=headers)
# print(response.json())
pins = response.json()['pins']
if pins:
for pin in pins:
print(img_url + pin['file']['key'])
# 获取最后一个pin_id作为下一次请求的参数
start_max = pins[-1]['pin_id']
i += 1
else:
print('获取响应无图片')
break
# 调用
craw(base_url)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
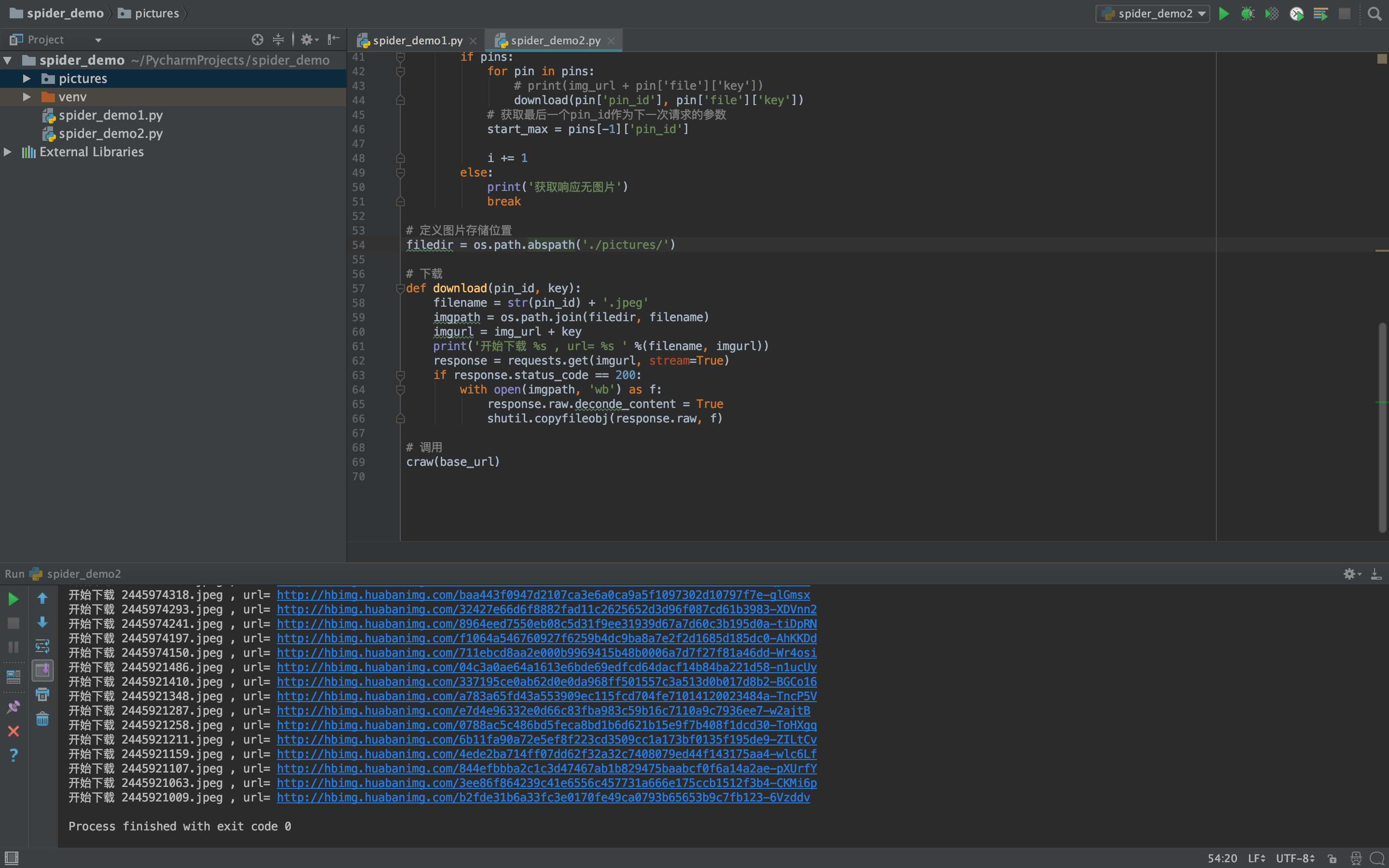
# 下载图片
将循环中打印图片url信息语句进行修改
download(pin['pin_id'], pin['file']['key'])
1
定义图片存储位置为绝对路径
# 定义图片存储位置
filedir = os.path.abspath('../pictures')
1
2
2
编写下载函数
下载函数需要两个参数,pin_id key。pin_id与指定后缀.jpeg拼接作为下载文件的文件名;文件名与图片存储位置拼接作为图片
的本地存储路径;key与img_url图片路径拼接,作为图片下载链接
最终通过requests获取响应结果,使用shutil将图片保存到本地(需要导包)
# 下载
def download(pin_id, key):
filename = str(pin_id) + '.jpeg'
imgpath = os.path.join(filedir, filename)
imgurl = img_url + key
print('开始下载 %s , url= %s ' %(filename, imgurl))
response = requests.get(imgurl, stream=True)
if response.status_code == 200:
with open(imgpath, 'wb') as f:
response.raw.deconde_content = True
shutil.copyfileobj(response.raw, f)
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 完整代码
import requests
import shutil
import os
# 定义基础url
base_url = 'https://huaban.com/explore/dianyinghaibao'
# 定义图片基础url
img_url = 'http://hbimg.huabanimg.com/'
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36',
'Accept': 'application/json',
'X-Request': 'JSON',
'X-Requested-With': 'XMLHttpRequest',
}
# 定义要获取的最大页数
pages = 5
# 爬取过程
def craw(url):
i = 1
# 设置起始最大id
start_max = 2529333588
while i <= pages:
print('获取第 %d 页数据' % (i))
# 定义参数
params = {
'k7yykous': '',
'max': start_max,
'limit': '20',
'wfl': '1',
}
response = requests.get(url, params=params, headers=headers)
# print(response.json())
pins = response.json()['pins']
if pins:
for pin in pins:
# print(img_url + pin['file']['key'])
download(pin['pin_id'], pin['file']['key'])
# 获取最后一个pin_id作为下一次请求的参数
start_max = pins[-1]['pin_id']
i += 1
else:
print('获取响应无图片')
break
# 定义图片存储位置
filedir = os.path.abspath('./pictures/')
# 下载
def download(pin_id, key):
filename = str(pin_id) + '.jpeg'
imgpath = os.path.join(filedir, filename)
imgurl = img_url + key
print('开始下载 %s , url= %s ' %(filename, imgurl))
response = requests.get(imgurl, stream=True)
if response.status_code == 200:
with open(imgpath, 'wb') as f:
response.raw.deconde_content = True
shutil.copyfileobj(response.raw, f)
# 调用
craw(base_url)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
# 总结
折腾了两个小时,(‘-ωก̀ )好困,淦